
History Keeps Changing. The Evidence Arrived While I Was Writing It.
And the window for democratic AI governance keeps closing...

This piece was developed with AI assistance (Claude / Anthropic). See the full methodological disclosure at the end of this article.
Note: This article is a Substack adaptation of a formal analytical essay developed across March–April 2026, updated April 7 to incorporate a breaking development that arrived as it was being published. The complete essay—The End of History, Revisited: A Compound Civilizational Stress Event and the 10% Path, with full footnotes, theoretical framework, and seven companion documents—is coming soon. The Agentic Accountability Playbook, a practitioner derivative, is here. The AI Governance Window Tracker, a structured monitoring instrument for tracking whether the binding-authority gap is narrowing or widening, is here. Both are free. A fuller account of the intellectual and personal genealogy behind this project, including the thinking-in-public lineage that shaped it, is available at Systems of Thought.
I. The Evidence Arrived While I Was Writing It
I started this project in early March 2026. The goal was to develop a rigorous analytical framework for a question I’d been circling for years: whether democratic governance retains the capacity to bind artificial intelligence before AI embedding makes binding governance structurally irrelevant. Not whether AI is dangerous, that’s a separate piece or project altogether, but whether the institutions we have can reach the problem in time.
Twenty-eight days of working sessions later, here is what happened while I was writing.
In the same week, the formal essay’s core argument was being drafted, a US airstrike near Minab, Iran, killed students in what had been a military compound, targeting data that had never been updated to reflect the conversion. Kevin Baker’s analysis in The Guardian documented what actually failed: not the model, not a rogue operator, but an execution environment that had no mechanism to distinguish confirmed intelligence from an assumption that had hardened into operational fact. The AI system performed exactly as designed. What was absent was the accountability layer that would have required the assumption to be verified before it became a strike authorization.
The same week, DeepMind released its Harmful Manipulation Critical Capability Level framework, the most rigorous voluntary AI safety evaluation yet published, built across nine studies and more than ten thousand participants in three countries, explicitly designed for external replication. A genuine achievement in voluntary governance.
The following week: Justin Rosenstein, a founding advisor to the Center for Humane Technology, former Facebook product leader who helped build the Like button, published a piece in Fortune naming Sam Altman, Dario Amodei, Demis Hassabis, Elon Musk, and Mark Zuckerberg as all caught in the same coordination failure he’d watched from inside Facebook: if I don’t do it, someone else will. He named the trap. He named the people in it. He proposed citizens’ assemblies as a governance mechanism.
In parallel, the federal legislative framework preempting state AI governance laws advanced. OpenAI shut down Sora and simultaneously announced a dedicated advertising infrastructure team, two moves separated by twenty-four hours. A Los Angeles court issued the first design-liability verdict in a social media case, establishing a legal precedent that AI companies are watching closely.
And today, as this article was finalized, Anthropic announced Project Glasswing: a new cybersecurity initiative built around Claude Mythos Preview, an unreleased frontier model that has already identified thousands of zero-day vulnerabilities across every major operating system and browser, including bugs that had gone undetected for decades. Anthropic declined general release on explicit dual-use grounds: the same capability that finds vulnerabilities can be used to exploit them. Instead, access is gated to a private consortium of twelve major tech partners with $100M in usage credits committed to defensive security. The governance structure around it is entirely voluntary. Anthropic’s own announcement acknowledges that comparable capabilities will reach other actors within months, regardless.
I am not describing a busy news month. I am describing the speed-deliberation asymmetry that the essay argues is the central structural problem of AI governance, playing out in real time, on the analyst, while the analysis was being written. The evidence for the thesis arrived faster than the thesis could track it.
That is not a rhetorical observation. It is a data point. And it is the reason this article exists now rather than after a longer editorial arc.
The argument that follows is organized around four conditions democratic governance requires to function: the authority to bind, the speed to keep pace, the coalition to hold, and the infrastructure to see clearly enough to act. Each of the events above is a case study in what happens when one of those conditions is absent. None of it is abstract.
II. The Predecessor Argument and Why It Doesn’t Close the Question
Before getting to the cases, the most important objection deserves a direct answer.
Propaganda has manipulated belief at scale since at least the 1920s. Mass media concentrated epistemic power in the hands of a small number of actors long before any AI system existed. Social media platforms engineered engagement optimization that fractured public discourse, amplified outrage, and accelerated political polarization across the 2010s. The mechanisms are well documented. The harms were substantial.
An honest account of where this project came from includes the reading that preceded it. Tobias Rose-Stockwell, an old friend from my west coast days, produced the definitive account of the predecessor regime in Outrage Machine (2023), and his ongoing Substack and podcast series have tracked its evolution in real time. That work was foundational here: both as the analytical baseline the essay builds from and as the clearest demonstration that the predecessor problem is documentable, legible, and partially addressable—which makes the question of what AI changes structurally sharper. Nicholas Carr’s Superbloom (2024) extended that arc; Yuval Noah Harari’s Nexus ran parallel. Reading them in sequence, from platform-era manipulation to AI-era epistemic stakes to the civilizational frame, is the progression the essay’s argument follows. If you haven’t read Outrage Machine, start there. It is the foundation on which the adequacy test stands.
The objection from this history is reasonable: if democratic institutions survived all of that, what makes AI categorically different?
Three things, and they interact.
Optimization without intent. Social media platforms were designed to maximize engagement. The harms, political fragmentation, epistemic distortion, and radicalization pipelines were byproducts, not goals, but they were at least byproducts of systems humans designed with specific commercial objectives. The output was legible at the level of the mechanism: the algorithm pushed engagement, engagement correlated with outrage, and outrage drove the observed effects.
Contemporary AI systems generate epistemic effects as emergent properties of optimization for objectives that have nothing to do with those effects. No one designed a large language model to produce political persuasion. Peer-reviewed research has documented that it does so at human-equivalent effectiveness. The failure mode is not at the intent layer; it is at the architecture layer. The mechanism the essay calls Property 1 is optimization without intent: systems that produce structurally significant effects without anyone having designed those effects in.Personalization with feedback closure. The predecessor regime operated at population scale. A newspaper, a TV broadcast, a social media algorithm—these produced shared epistemic environments. Distorted ones, yes. Manipulated ones, sometimes. But environments whose effects were at least in principle visible across the population that shared them. You could study them. Journalists could document them. Collective recognition was possible.
AI systems operating at the individual scale with personalized output and feedback-responsive conversation produce something structurally different: individually constructed epistemic environments that are not comparable across persons. What I receive from a personalized AI interaction, what you receive, and what a third person receives are not versions of a shared environment. They are distinct constructions, each shaped by the interaction history that preceded them. The mechanism for collective recognition, the shared surface that makes “we are all seeing the same distortion” a legible claim, is being dissolved at the architectural level.Speed-deliberation asymmetry. Democratic governance is slow by design. Deliberation takes time. Coalition formation takes time. Legislation takes time. Judicial review takes time. In the predecessor era, those timescales were mismatched with the pace of platform change, but the mismatch was not absolute; legislation eventually addressed some of what social media had done, even if inadequately and late.
The current asymmetry is of a different order. OpenAI shuttered Sora and built a dedicated advertising team in twenty-four hours. Hollywood’s substantive governance mobilization, opt-out demands, union engagement, and studio negotiations were rendered moot by a product exit executed faster than any deliberative process could keep pace. The governance mechanism is not slow relative to the problem. It is operating at a categorically different speed, such that even a well-functioning deliberative system cannot keep pace with actors who can move decisions at the speed of an org chart update.
These three properties combine to create a governance challenge that is structurally different from the predecessor problem; not just harder, but different in kind. Governance frameworks adequate to the predecessor problem are not adequate to this one, because the failure modes are at different layers. The question is not whether governance exists. The question is whether governance can reach the layer where actual failures occur.
That is the adequacy test. The March and April 2026 cases are what it looks like when applied.
III. Minab: The Authority to Bind
The most important thing Kevin Baker documented about the March 2026 airstrike near Minab is something the initial coverage mostly missed.
The coverage asked whether the AI model could be trusted. That is a reasonable question, and it is the wrong one.
Baker’s harder question was whether the execution environment, the system that converted targeting data into strike authorization, had any mechanism to distinguish confirmed intelligence from an assumption that had never been verified against current conditions. A military compound had become a girls’ school. The update never propagated. The assumption never got flagged as an inference. It hardened into operational fact and became the basis for a strike.
The AI system performed exactly as designed. The failure was not at the model layer. It was at the accountability layer, the layer that governs what the system is permitted to treat as confirmed without a verification record attached. That layer did not exist.
This is what the essay calls the inference-flagging gap: the structural absence of any mechanism to tag an input with its epistemic status, confirmed, inferred, unverified, time-sensitive, before it becomes operationally binding. An audit trail records what a system did. Inference-flagging governs what a system is permitted to do without a verification record. Both are required for execution-environment accountability. Neither is currently specified as a requirement in any binding governance framework.
The coverage that followed asked whether AI should be used in military targeting. That is also a reasonable question. But it is downstream of the structural question: whether governance frameworks that evaluate model outputs, content filters, bias audits, capability benchmarks, and hallucination rates address the layer at which this failure occurred. They do not. Certifying that a model performs accurately on its training distribution does not create a mechanism to flag an assumption as uncertain before it becomes a strike authorization. These are different problem surfaces.
The first condition democratic governance requires is the authority to bind—not just the authority to regulate what models can output, but the authority to reach the execution environment architecture where consequential failures actually occur. The Minab case is a demonstration of what that authority’s absence looks like when the stakes are not hypothetical.
This is not an argument that AI caused the Minab strike. It is an argument that the governance frameworks being developed now will face this exact failure mode, in targeting systems, in clinical decision-support systems, in financial compliance infrastructure, and that frameworks adequate to the predecessor problem will not be adequate here.
IV. The CCL: The Infrastructure to See
In the same week the Minab case was being analyzed, DeepMind released the Harmful Manipulation Critical Capability Level, which it accurately described as a rigorous empirical measure of manipulative capability in AI systems.
The CCL is worth taking seriously as a governance instrument. Nine studies. More than ten thousand participants across the United Kingdom, the United States, and India. Cross-domain coverage across finance and health contexts. Measuring both efficacy, whether AI systems actually change beliefs and behavior, and propensity, whether systems use manipulative tactics even when not explicitly instructed to. Published with an explicit invitation to external replication, which is a design feature that distinguishes it from most voluntary commitments in this space. This is not performative governance. It is a meaningful attempt to make manipulative capability measurable.
And it is not sufficient to solve the problem described by the three properties.
The CCL measures deliberate manipulation: systems that are instructed to be manipulative, or that demonstrate a propensity for manipulative tactics when instructed. That is the predecessor-era governance problem: the intentional-misuse version of manipulation that regulators and researchers have been developing frameworks to address since social media platforms were scrutinized for algorithmic amplification of harmful content.
The three properties describe structurally distinct things. Property 1 produces epistemic effects as emergent byproducts of optimization for unrelated objectives, not because anyone designed the manipulation in. Property 2 operates through individually tailored feedback loops, producing effects that are not visible at the population level, unlike voluntary frameworks. Property 3 means that by the time the evaluation framework identifies a manipulation pattern, the system generating it has already been updated, deprecated, or replaced.
A system certified fully compliant with the CCL may simultaneously be ungoverned on all three of these problem surfaces. The certification indicates that the system doesn’t exhibit a tendency to manipulate when instructed. It tells you nothing about what the system produces as a structural byproduct of advertising-integrated optimization operating at conversation speed with individual feedback closure.
The fourth condition is the infrastructure to see clearly enough to act. Seeing clearly requires tools that can evaluate emergent optimization effects—not just intentional misuse. Those tools do not currently exist in an accessible, verifiable form. The CCL is the most rigorous attempt yet to build an evaluation infrastructure for the predecessor problem. It demonstrates both what that infrastructure can achieve and its ceiling. Neither observation is a criticism of the CCL’s design.
The adequacy test does not ask whether a governance framework is well-designed. It asks whether the framework reaches the problem surface where the actual failures occur. Applied to the CCL, the answer is: not yet, and not by design.
V. Rosenstein and the Race: Speed and Coalition
In late March 2026, Justin Rosenstein published a piece in Fortune that deserves more attention than it’s received.
Rosenstein helped build Facebook's Like button. He was a founding advisor to the Center for Humane Technology, the organization that documented social media’s manipulative design patterns and brought them into mainstream policy awareness. He is not an outside critic of the technology industry. He was present for the predecessor version of the dynamic he is now describing.
His argument in Fortune is that AI is structurally repeating the same mistake that social media made, and that the people who know this are not stopping it. He names them: Sam Altman, Dario Amodei, Demis Hassabis, Elon Musk, and Mark Zuckerberg. Each caught in the coordination failure he had watched from inside a decade earlier: if I don’t do it, someone else will.
The analytically significant thing about Rosenstein’s piece is not the naming. It is the simultaneity of the naming and the continuing. The participants in the race are not unaware of the dynamic. They are not confused about what they are building or the risks. They are operating within a structural coordination failure that individual awareness cannot resolve, because awareness of the trap does not change the incentive structure that makes it a trap.
This is the third condition: the coalition to hold. A reform coalition requires not just public demand, though Blue Rose Research’s 2026 polling documents cross-partisan support for AI governance across Trump voters, Biden voters, and swing voters, which is a necessary condition, but the institutional capacity to translate that demand into binding action faster than the problem surfaces. The speed asymmetry is not incidental to the coalition problem. It is part of what makes coalition formation structurally difficult: the problem the coalition is forming around keeps shifting before it can stabilize.
Rosenstein’s proposed solution is citizens’ assemblies, deliberative bodies modeled on Ireland’s processes for marriage equality and abortion, and analogous processes in Taiwan, Belgium, and the United Kingdom. The proposal’s democratic legitimacy is genuine. Cross-partisan deliberative assemblies are meaningfully different from captured regulatory processes, and the empirical record of what they’ve achieved on contested social questions is real.
The adequacy test applied: a citizens’ assembly that cannot evaluate emergent optimization effects, personalized feedback closure operating at the individual scale, or conversation-speed asymmetry is deliberating about a governance problem that exceeds its members’ epistemic access. Not because assembly members are unsophisticated, but because the tools required to evaluate these properties don’t currently exist in accessible, verifiable form. The fourth condition (infrastructure to see) is the precondition for the third (coalition to hold). Assemblies require the epistemic infrastructure that makes the problem legible before they can govern it effectively.
This is not an argument against assemblies. It is an argument that assemblies are necessary but insufficient, and that the missing piece—accessible technical infrastructure for evaluating the three structural properties—is itself a governance requirement, not a precondition that will arrive on its own.
VI. Glasswing: The Speed to Keep Pace
Today, Anthropic announced Project Glasswing.
The announcement is worth reading carefully, because it is unusually honest about the problem it cannot solve.
Claude Mythos Preview, an unreleased general-purpose frontier model, has already identified thousands of zero-day vulnerabilities across every major operating system and browser, including bugs that had survived undetected for decades. The same capability that finds vulnerabilities can be used to exploit them. Anthropic declined general release on those grounds and built a gated structure instead: twelve major tech partners, forty additional critical infrastructure organizations, $100M in usage credits committed to defensive security work.
The governance architecture around it is entirely voluntary. No independent oversight. No binding access criteria. No regulatory framework governing who gets in, on what terms, or what happens when these capabilities diffuse; which Anthropic’s own announcement acknowledges will happen within months regardless.
This is not a criticism of Project Glasswing. The gated release structure is real. Vulnerability disclosures are handled through coordinated disclosure, and patches are confirmed before details are published. The consortium includes the organizations whose software underpins most of the world’s critical infrastructure, and the Linux Foundation’s observation that open-source maintainers have historically been left to manage security alone is exactly right. This is a serious attempt to use a dangerous capability defensively before it proliferates offensively.
The adequacy test applied: a voluntary consortium governs willing participants who join it on the timeline they agreed to, without binding obligations that survive a decision to exit. Anthropic has acknowledged that the capability threshold has been crossed. The governance structure built around that acknowledgment is not binding, not externally verified, and explicitly time-limited by the developer’s own estimate of how long comparable capabilities remain gated.
This is what the second condition looks like when it’s absent: the speed to keep pace. Not the speed to match individual product decisions, that is impossible, but the speed to establish binding rules at the capability class level, such that when this capability diffuses to the next actor, the governance requirement travels with it. That architecture does not exist. What exists is a consortium of willing partners and a 90-day reporting commitment.
The essay’s argument was written before Glasswing. Glasswing is the argument.
The essay's argument was written before Glasswing. Glasswing is the argument.
VII. The Dual Clock and the 10% Path
The essay’s core diagnostic is two clocks running simultaneously.
The embedding clock is technically determined. It tracks the pace at which AI capability becomes load-bearing in critical infrastructure: financial compliance systems, clinical decision support, military targeting, and administrative adjudication. Once AI is sufficiently embedded in these systems, governance shifts from prospective rulemaking, setting rules before deployment, to retroactive regulation of entrenched incumbents who have substantial leverage over the regulatory bodies trying to govern them. That is a qualitatively harder governance problem.
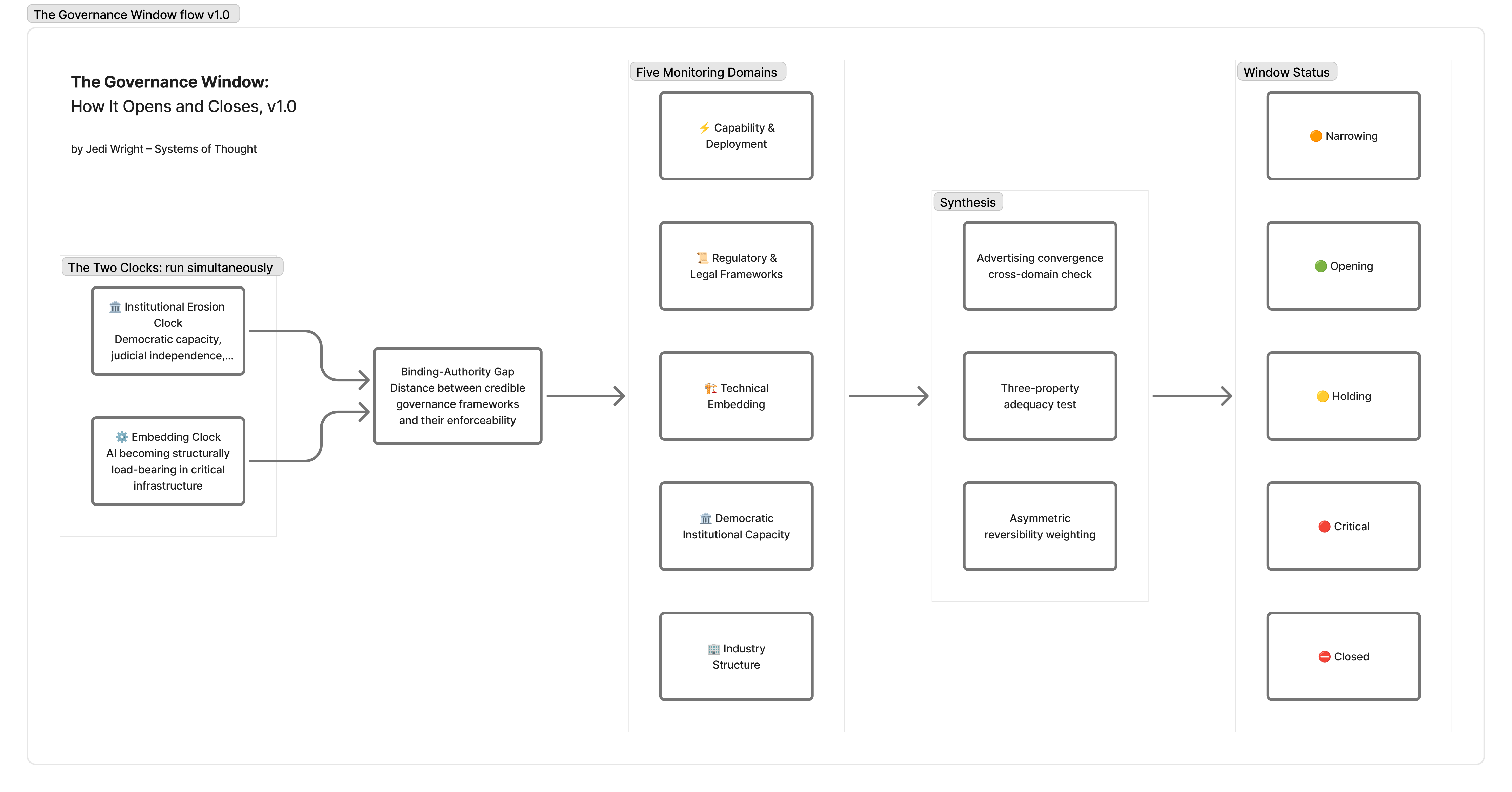
The institutional erosion clock is politically determined. It tracks the pace of degradation of democratic institutional capacity: judicial independence, epistemic commons, civil society infrastructure, and the coalition-formation conditions that binding governance requires. This clock runs independently, but is not independent: ungoverned AI deployment actively degrades the epistemic conditions and coalition-formation capacity that democratic renewal requires. The clocks interact. Losing the governance window forecloses both.
The tracker’s first full assessment, run on April 5 against all five monitoring domains, returned a window verdict of Narrowing, approaching Critical. The tightened window estimate is 2025–2030.
That is not a comfortable number. It is the structural argument about what the two clocks, running simultaneously in their current configurations, produce as a verdict about the time available.
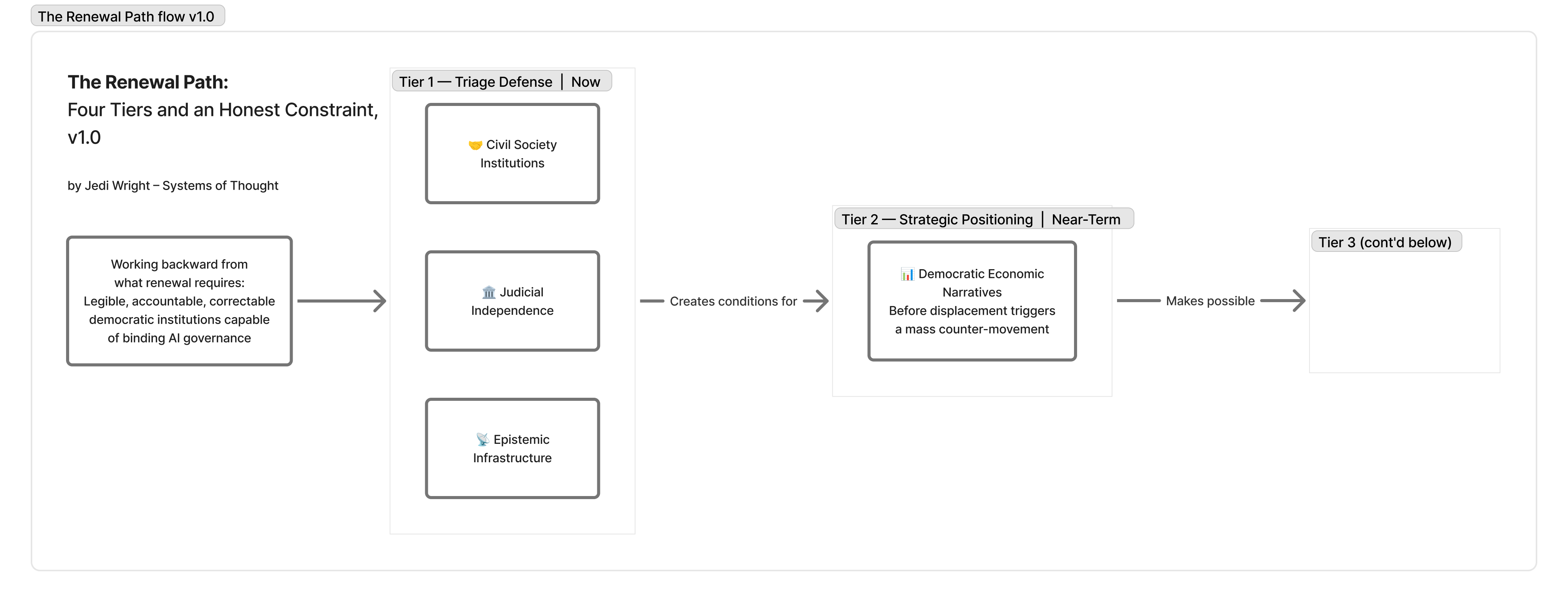
The essay calls the renewal scenario the 10% path—not a prediction, but an honest assessment of probability given current conditions, and a structural argument about what that path requires worked backward from its conditions. Three defensible action tiers emerge from that analysis.
The first is triage defense: judicial independence, epistemic infrastructure, and civil society institutions. Not because these are sufficient, but because they are the preconditions for everything else. A governance coalition that forms without functioning courts, without shared epistemic ground, without civil society institutions capable of translating public demand into political pressure cannot hold.
The second is strategic positioning: democratic economic narratives before AI displacement trigger a Polanyian counter-movement. The cross-partisan polling signal is real, but it is a latent preference, not a political coalition. The window for translating that preference into binding governance closes faster than the preference disappears.
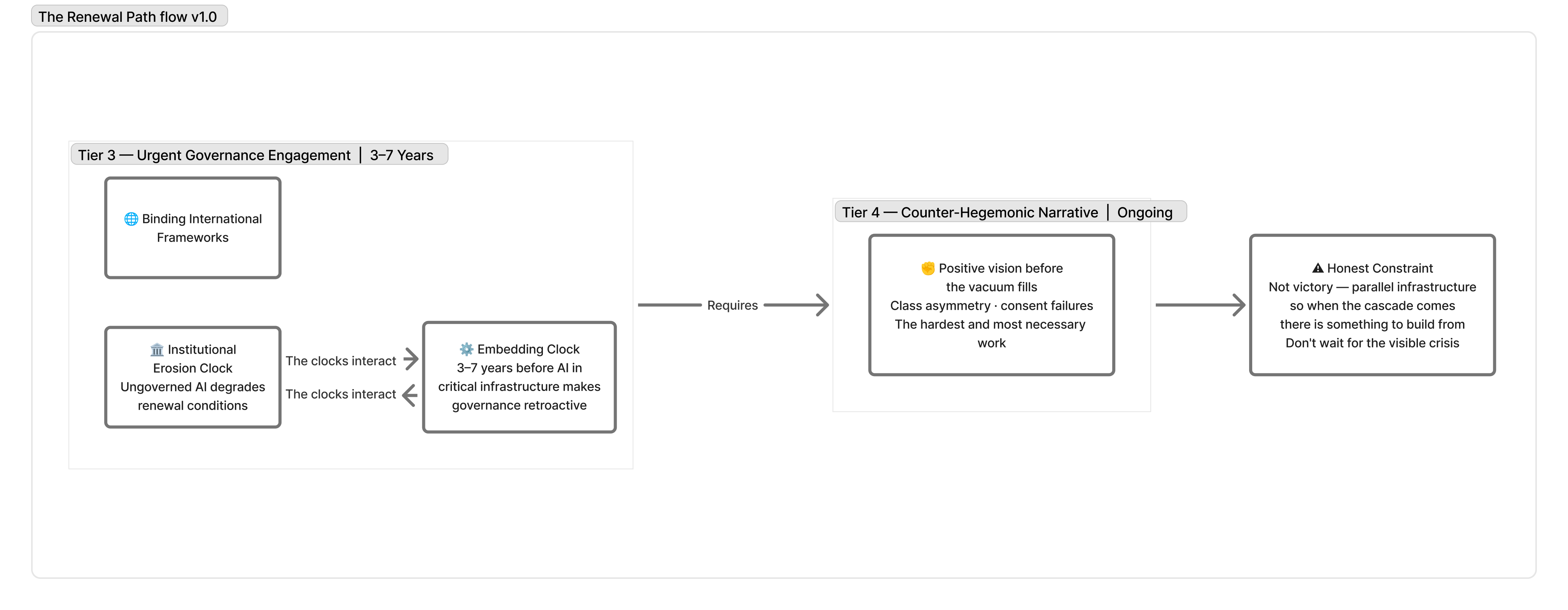
The third is urgent engagement with binding international frameworks: the architecture that can survive the minus-US scenario, establish baseline requirements across jurisdictions, and close the gap between voluntary commitments and enforceability faster than the embedding clock runs. The EU AI Act’s high-risk enforcement provisions come into effect in August 2026. That is a deadline, not a guarantee.
The honest constraint on all of this is that none of the tiers guarantees the outcome they are working toward. The 10% path is not optimism. It is the structural argument that renewal remains possible, that the window has not closed, and that the conditions for closing it faster are observable and partially addressable. The cases in this article, Minab, the CCL, Rosenstein, and Glasswing, are not arguments that the window is closed; they are arguments about what closing looks like in operational detail and what the four conditions require to prevent it.
VIII. What the Four Conditions Require
The origin post in this series closed on the constraint that produces everything that follows: a system that must perform without its designer present requires that the designer build the designer’s judgment into the system before leaving. The constraint does not change. The medium does.
The problem at scale is that democratic governance is performing without the four conditions it requires.
The authority to bind—not just to regulate model outputs, but to reach the execution environment architecture where consequential failures occur. The Minab case shows what the absence of that authority looks like in practice. Governance frameworks that certify model performance without specifying accountability for execution environments are governing the wrong layer.
The speed to keep pace—not matching the speed of individual product decisions, which is impossible, but establishing binding rules at the capability class and deployment vector level, such that exiting one product into another doesn’t exit the governance requirement. Hollywood’s mobilization didn’t fail because it was slow. It failed because the governance architecture it was operating within was product-specific rather than capability-class-specific. Glasswing didn’t fail, but the voluntary structure around it will not hold when the capability diffuses, and Anthropic said so in the announcement.
The coalition to hold—cross-partisan, institutionally durable, capable of translating latent public demand into binding action on a timeline that competes with the embedding clock. The Blue Rose polling is a necessary condition. It is not sufficient without the institutional capacity to act on it and the epistemic infrastructure to make the problem legible to deliberating citizens.
The infrastructure to see clearly enough to act—evaluation tools that can assess emergent optimization effects, individual feedback closure, and speed-deliberation asymmetry, not just intentional misuse. The CCL establishes what the predecessor-era evaluation infrastructure can achieve. The gap between that and what the three structural properties require is the infrastructure gap this condition names.
The first thing any of these conditions requires is an honest account of their current status. The governance window is narrowing. The cases are real. The conditions are specific. The path remains open.
This article is that account, at this moment.
A note on investment: this essay was developed as part of a broader analytical project spanning approximately 106–110 working sessions over twenty-eight days (March 10–April 7, 2026), with an estimated 72–106 hours of active session time and an additional 20–30 percent in author overhead: review, between-session deliberation, independent source verification, and the intellectual work of deciding what to contest.
Total estimated investment across the full project suite: essay, policy framework, governance tracker, legibility framework, practitioner playbook, and publication work, runs to approximately 87–138 hours, with a midpoint near 112. The essay itself accounts for the largest share of that investment; the remaining documents derive from and extend its analytical core.
These figures are drawn from session documentation and are pending final verification against the Project Record; they are offered as a best current estimate rather than a confirmed accounting. They do not include independent reading and research time; the primary sources, theoretical frameworks, and governance literature the essay draws on represent a body of engagement that predates and exceeds the session record.
And it’s offered not as a credential but as a corrective to the compression illusion the third-order problem names: the synthesis took minutes for the AI to produce and weeks for the author to direct, challenge, verify, and refine. The ratio is the point.
This article is part of an ongoing project. The formal essay and Agentic Accountability Playbook below represent the analytical and practitioner layers of the same argument. Future installments will track the governance window as it develops, including quarterly assessments via the AI Governance Window Tracker, a structured five-domain monitoring instrument that assesses whether the binding-authority gap is narrowing or widening; case studies on execution-environment accountability; and the practitioner framework for teams deploying AI in consequential contexts. If you’re working on AI governance, deployment accountability, or democratic institutional resilience and want to engage with the peer review process, the documents are open.
The complete analytical essay—The End of History, Revisited: A Compound Civilizational Stress Event and the 10% Path, with full footnotes, theoretical framework, and its companion documents, is coming soon.
The Agentic Accountability Playbook—a practitioner derivative for teams deploying AI in consequential contexts, is available for peer review here: The Agentic Accountability Playbook v0.1.
The AI Governance Window Tracker—a structured five-domain instrument for monitoring whether the binding-authority gap is narrowing or widening, is here: The AI Governance Window Tracker v1.5 (public agentic skill coming soon).
© 2026 UX Minds, LLC. Licensed under CC BY-NC-ND 4.0. Systems of Thought is a publication of UX Minds, LLC.
DISCLOSURE: AI-Assisted Research and Methodological Note
This article originated in extended Socratic dialogue with Claude (a large language model produced by Anthropic) and was developed through iterative AI-assisted research, drafting, and editorial refinement. The intellectual direction, choice of frameworks, critical challenges, and core arguments were human-led; Claude functioned as a structured thinking partner that the human interlocutor could interrogate, redirect, and contest.
This disclosure is placed here because publishing an AI-collaborative work without foregrounding that fact would be a performative contradiction of this article’s own argument about illegibility and epistemic infrastructure.
Readers should be aware: (a) the synthesis of scholarly frameworks was AI-assisted and has not been independently verified against all primary sources; (b) fluency of prose does not guarantee rigor of underlying scholarship; (c) the primary sources, footnotes, and full scholarly apparatus are documented in the formal essay (coming soon, links will be added here once available); readers are encouraged to consult them directly there.
Legal note: Produced using Claude under Anthropic’s Acceptable Use Policy, which permits publication of AI-assisted outputs. The human author asserts copyright over intellectual direction and editorial judgment. See: https://www.anthropic.com/legal/aup